0
items in Cart
In this Diablo 2 Resurrected guide from Goldkk.Com, we are breaking down Absorb - this is an interesting modifier of items that's maybe not the most commonly used or even understood, but is actually really powerful and has the potential to entirely nullify damage, actually even cause incoming elemental damage to heal you.
For example, in gameplay, you've got the unique D2R items: Hellmouth War Gauntlets which give you +15 to fire absorb, and Dwarf Star Rings which give you +15 to fire absorb as well, then you can sit in the middle of some hydras there not taking any damage at all. Why is that? Let's take a closer look.

With Absorbs in Diablo 2 Resurrected, it's important to understand the order of operations, you have two types of absorb:
Type 1: Flat absorb such as that given by the Hellmouth War Gauntlets that plus 15 fire absorb - is a flat 15 points of damage.
Type 2: Percentage-based absorb such as the Dwarf Star Rings that is a percentage of damage, you can stack up to 40% absorb. You cannot stack beyond 40 absorb in this case: if you've stacked a total of 30 fire absorbed 15 plus 1, but just to know that there is a cap at 40, so stacking beyond that would be redundant.
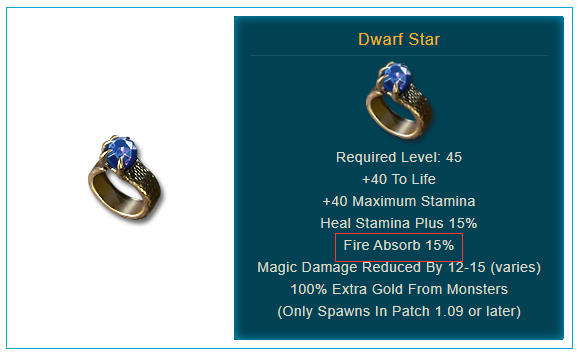
So the order of operations is very important to understand how absorption works in Diablo 2 Resurrected. Let's imagine that you took 1,000 points of fire damage, in this case, your character has a ridiculous 95 fire resistance thanks to the Guardian Angel, what would first happen is:
1. The first thing that is calculated is your fire resistance on that thousand damage reducing it to a mere 50 points of damage
2. The next thing that is calculated is your absorb percentage, so in this case, we would take 15 plus 15 equaling 30 fire absorb
We would subtract 30 percent from that 50 points of remaining damage which equals 15 points of damage which is reduced, and it also adds 15 points of damage which is healed, so we add up the damage that was healed and the damage that was reduced 15 plus 15 equals 30 points of damage which is reduced. So we have reduced 30 points of damage from that remaining, 50 damage that is still coming through, for a total of 20 damage still remaining. The absorbed damage reduction and the absorb heal works at the same time, you can kind of think of it like this in more simple terms. If you see 15 fire absorb that actually reduces fire damage by 30 percent, because you get 15 reduction and 15 heal that happens at the same time, so that's kind of an easy way to calculate that. So if we have two absorbed rings at 15 each, we have 30 absorb, so basically, we're getting 60 fire damage reduction from those two absorbs
We have 20 points of damage left, but we still have the last order of operations which is our flat fire absorb from our helmet gauntlets which give us a flat 15 fire absorb, so we have 20 points of damage remaining. From that 20 points of damage remaining, we of course subtract 15 and we add 15. So we subtract 15 which gives us 5 points of damage remaining and then we add 15 onto that which gives us a total of 10 points of life healed.
To help you understand the works of absorb items in D2R, here we do the calculation again with a slightly different example - a fire resistance of 75 percent:
Example: 1000 Fire Damage at Fire Resistance 75%, with 30% Fire Absorb, and 15 Flat Fire Absorb
Character Damage Calculation
1000 - 75% = 250
250 - 30% = 75 (Damage Removed) and 75 Damage Healed (At Same Time)
Total Character Damage = 250 -150 = 100 Damage
15 Flat Absorb Next
100 - 15 (Reduced) and 15 Healed = Total of 70 Damage Taken
Here we take 1000 points of damage and our fire resistance removes 75 of that, so 1,000 minus 75 equals 250 damage remaining. So from our remaining 250 damage, we subtract 30 percent from our Dwarf Star Rings, so that equals 75 damage removed, so basically 250 minus 30 equals 75. The confusing part is that at the same time as we remove 30 damage, we also heal the amount of damage that was removed, so 75 damage was removed and 75 damage was also healed at the same time. Combining these two, we have a total of 150 damage reduction, so the total character damage would be 250 minus 150 which only leaves 100 damage remaining.
Then the next order of operations is our flat damage that comes from the Hellmouth War Gauntlets in this case. From our remaining 100 damage, we also have 15 flat damage absorb as well, so 100 minus that 15 flat damage which is reduced and also with absorb that 15 is also healed at the same time, so we take 15 plus 15 for a total of 30 damage removed which leaves a total of 70 damage taken to the character.
So that's how the Absorb works in Diablo 2 Resurrected. When stacking lightning absorbs in your resistances, it becomes possible to do some pretty interesting things such as negate and nullify even some of the most powerful damage and dangerous creatures in the game, this can be really effective for target farming certain areas with certain powerful monsters.
